
The Paradox Nobody Talks About
Your SOC processes 50,000+ alerts daily. You’ve invested in SIEM, EDR, NDR, and threat intelligence. Your team works long hours. Yet critical attacks still slip past. This isn’t a visibility problem. It’s an operational architecture problem.
The uncomfortable truth: SOCs drowning in alerts aren’t failing because they don’t see threats. They’re failing because they can’t convert visibility into decisions fast enough.
The Three Operational Realities Destroying SOC Effectiveness
Reality 1: Analysts Are Cognitively Overloaded
The human brain doesn’t operate effectively in a highly critical environment every hour. Let’s assume it can take from 40 to 60 quality decisions. A typical analyst receives 400+ alerts in an 8-hour shift.
The math is impossible: 400 alerts ÷ 40-60 quality decisions = cognitive failure.
What happens:
- Hours 1-2: Careful analysis
- Hours 3-4: Pattern matching dominates
- Hours 5-6: Real threats blend into noise
- Hours 7-8: Alert fatigue leads to dismissals
By the end of the shift, your best analyst has mentally checked out.
Reality 2: High-Risk Signals Lack Pre-Analysis Context
When a genuine threat arrives, it comes stripped of investigation:
- No asset criticality (is this production or test?)
- No user context (service account or lateral movement).
- No threat of intelligence enrichment (known patterns or novels?)
- No behavioral baseline (is this normal?)
Result: An alert that could be triaged in 2 minutes requires 20-40 minutes of investigation. Analysts waste months annually on first-principles analysis.
Reality 3: Alert Quality Degrades with Every New Tool
The typical expansion pattern:
- Year 1: SIEM → 10,000 alerts/day
- Year 2: Add EDR → 25,000 alerts/day (duplicate alerts across platforms)
- Year 3: Add NDR → 50,000+ alerts/day (three platforms contradict each other)
Each new tool was designed for its specific problem and not to integrate seamlessly.
Result: fragmented workflows, conflicting severity classifications, and separate dashboards.
More tools without workflow redesign = exponentially more noise, not better detection.
Why Alert Volume Strategies Fail
Organizations typically respond to alert overload by adding more layers:
- More monitors → more raw data
- More analysts → same burnout rate, just slower
- More tools → more fragmentation
This is like trying to bail out a boat while water pours through a hole in the hull. You’re not fixing the leak; you’re just hiring more people to bail. The real problem isn’t quantity. It’s signal-to-noise ratio and decision velocity.
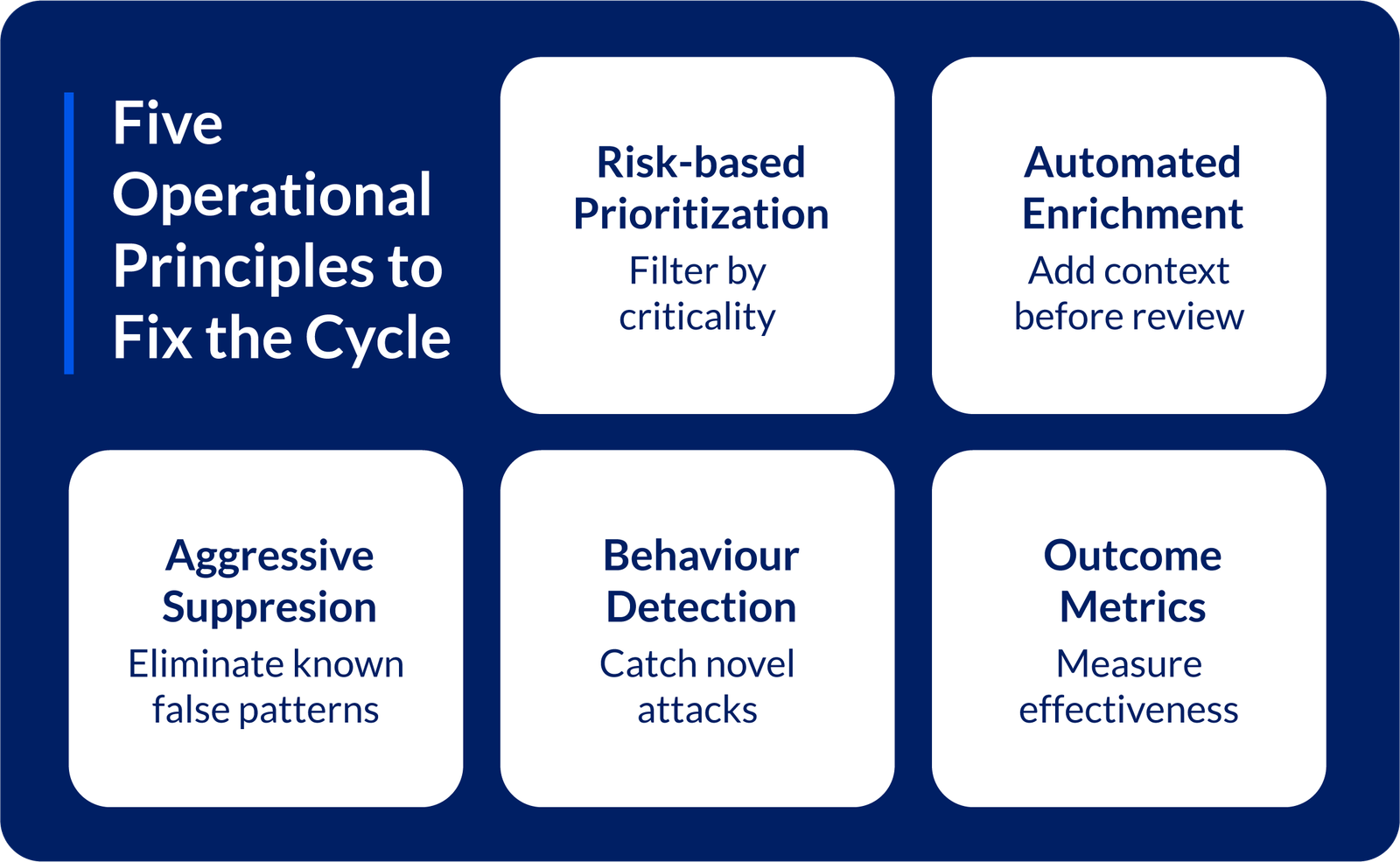
The Operational Fix: Five Principles That Actually Work
Principle 1: Risk-Based Prioritization, Not Volume-Based
Stop treating all alerts equally.
Implement automated risk scoring:
- Score each alert on asset criticality × threat severity × business impact
- Route low-risk alerts to automated response (no human triage)
- Escalate only high-risk alerts to analysts
Result: Analysts focus on 200 high-quality alerts instead of 5,000 mixed ones
Principle 2: Automated Enrichment Before Human Eyes
Stop requiring analysts to investigate raw data.
Enrich every alert automatically with:
- Asset intelligence (production criticality, data sensitivity, owner)
- User behavior analysis (is normal for this user?)
- Threat intelligence enrichment (have we seen this signature before?)
- Behavioral baselines (standard deviations from normal)
By the time an analyst sees an alert, 80% of the investigation is complete. They review and decide – not investigate and wonder.
Principle 3: Aggressive False Positive Suppression
Stop letting known benign patterns consume analyst time.
Automate:
- Signature-based suppression (suppress alerts matching known legitimate activity)
- Behavioral baselines (exclude normal patterns automatically)
- Time-of-day filtering (suppress predictable maintenance windows)
- Known service account activity (auto-whitelist routine activity)
Organizations that suppress 70%+ of false positives see analyst productivity jump 300%.
Principle 4: Behavior-Based Detection Alongside Signatures
Signature-based detection caught yesterday’s attacks. Behavioral detection catches today’s novel attacks.
Shift to behavior-based approaches:
- Anomaly detection flags deviations from baseline (catches new malware)
- User entity behavior analytics (UEBA) detects lateral movement patterns
- Network traffic analysis (NTA) identifies command-and-control even with unknown malware
This catches attacks that evade signature matching – the attacks that currently go undetected.
Principle 5: Measure Outcomes, Not Activity
Replace vanity metrics with operational reality metrics:
Stop measuring:
- Alerts processed (activity, not effectiveness)
- Tickets closed (effort, not impact)
- SLA compliance (speed, not quality)
Start measuring:
- Mean Time to Detect (MTTD): How fast from attack to detection?
- Mean Time to Respond (MTTR): How fast from detection to containment?
- Dwell Time: How long do attackers stay inside?
- False Positive Rate: How much time is wasted on noise?
- Threat Detection Rate: What % of real attacks do we catch?
A SOC that detects 500 alerts with 85% accuracy is dramatically more effective than one detecting 50,000 alerts with 10% accuracy – even though activity metrics suggest otherwise.

The Operational Shift: From Monitoring to Decision-Making
This isn’t a tool problem. This is an operating model problem.
Effective SOCs operate as decision centers, not monitoring centers.
| Traditional SOC | Operational SOC |
|---|---|
| Monitor everything | Understand the critical |
| Analysts investigate raw data | Systems gather context; analysts decide |
| Escalate to incident response | Execute response during detection |
| Quarterly rule tuning | Continuous daily improvement |
| 90% time on noise | 70% time on genuine threats |
The Business Case: The Hidden Cost of Alert Overload
A false positive requiring 30 minutes of analyst investigation costs:
- Direct: 30 min × $75/hour = $37.50
- Context switching: 10 min reorientation = $12.50
- Fatigue accumulation: 1% toward burnout = $5
- Opportunity cost: 30 min not on proactive work = $25
- Total per false positive: ~$80
If your SOC processes 1,000 alerts/day with 85% false positive rate:
- 850 false positives/day × $80 = $68,000/day
- Annualized = $17M/year spent on noise
Organizations that reduce false positives from 85% to 30%:
- Save $11M annually on analyst time
- Improve MTTD by 40%
- Improve MTTR by 60%
- Reduce dwell time by 70%
- Increase threat detection rate from 40% to 85%
This is a business transformation, not an optimization.
The Path Ahead: Your Operational Checklist
1. Audit your alert volume:
How many alerts per day?
What’s your false positive rate?
2. Measure analyst time:
Track time spent on investigations vs. triage vs. novel analysis
3. Implement risk scoring:
Route alerts based on impact, not just detection
4. Automate enrichment:
Build context before human review
5. Suppress known benign patterns:
Eliminate predictable noise immediately
6. Shift metrics:
Replace activity metrics with outcome metrics
7. Integrate response:
Connect detection and incident response workflows
The SOC that escapes alert overload isn’t the one with the most tools. It’s the one that optimizes its operating model – how decisions are made, how context flows, and how automation handles repetitive work.
The Real Question
The question isn’t whether you can handle more alerts.
The question is:
Can your analysts make better decisions with the data you already have?
If the answer is no, adding more tools won’t help.
Your operating model requires a redesign.
The difference between drowning SOCs and thriving ones isn’t tools.
It’s an operational architecture.
Don’t add more volume. Fix the signal.


